Today we are announcing the launch of the Startup Genome Compass, a web application designed to aid startups in assessing their performance and benchmark themselves against firms with similar properties.
In addition to the introduction of the Startup Genome Compass, we are releasing a second report that goes deeper into analysis of startups; mainly the implications of prematurely scaling their operations.
The Startup Genome Compass is a result of further research into the properties of startups, and what makes them tick. Several months ago, we published the first Startup Genome Report. The report received tremendous attention, and wide publication. Over 3,200 firms filled out our assessment, and we received excellent feedback and support from the startup ecosystem.
This blog post describes how the Startup Genome Compass was built, and some of the magic behind the curtain. Before I begin, it may be worthwhile to remind the readers about the goal of the project:
The Startup Genome project aims to increase the success rate of startups by deciphering how startups are built, and give entrepreneurs data, tools and recommendations to improve their performance. We try to put quantitative measures on almost all aspects of startup performance in order to improve decision making during the lifetime of firms.
The "heart" of our technology lies in the machine learning process used to identify the startup’s type and stage. The credit for building and fine tuning the machine learning engine goes to Ertan Dogrultan, who became an indispensable member of the Startup Genome team in June. I describe the machine learning process later in the blog post. Before that, here's a short introduction to Machine Learning.
The idea behind machine learning is simple - given a set of examples, called the training sample, an algorithm "can learn" the common patterns in these examples, and try to find these patterns in a new set of data. For example, we can give an algorithm a set of peoples' heights and genders. The algorithm can then learn that men are, on average, taller than women. When the algorithm is given a new set of data on people later, it can predict their average height from their gender.
What machine learning does best is to identify the relevant parameters that can describe a pattern in the data succinctly, learn those patterns and then predict them. In other words, it is good at identifying correlations and interpolating from data.
What machine learning does not do, typically, is explain the process that causes these correlations, or what causes what. I touch a little bit on that later, in the part titled "the usual suspects", but in general, readers of our report should always remember that correlation does not imply causation.
In the next few paragraphs, I will describe the analysis process in the order it was performed, leading to the development of the Startup Genome Compass.
Data Collection
Given the overwhelming response to our report, we were able to collect a significant amount of data. Some researchers have estimated that the Startup Genome now has the largest collection of startup data in the world. The role of our data collection in this phase was less exploratory and more targeted. The major change from version 1 of the survey was addition of specific questions that could help identify startup type and stage. In addition, we collected more "generic" information (such as age and education information) to be able to compare our findings with previous research about the startup phenomena. Another improvement over the previous survey was making it dynamic - during the survey, the questions changed on the fly according to firms' answers, thus allowing us to ask more questions.
Machine Learning for Classification
In order to analyze a firm, we need to classify it to two types of groups - what type of firm it is, and in which stage it is. It is important to understand the difference between a behavioral stage and an actual stage of a firm.
A behavioral stage is determined according to the firm's actions, e.g., how much money it spends on user acquisition, or how many employees it has hired. An actual stage is determined by a firm's market success factors. Examples are the user growth of the firm, its total number of users and other measures. In total there are several tens of parameters used for each classification.
A classic classification process has two parts - in the first part, called training, an algorithm is given examples of exogenously classified data. This data is used to train the algorithm to be able to analyze non-training data. In the second part, classification is run on the non-classified data, and the results are tested for accuracy.
Our training data was created by our team. We manually classified several hundreds of firms for types, behavioral stage and actual stage. It was a lot of work, but the more firms we classified, the more accurate our algorithm becomes. Pandora works similarly, actually. Every song you hear has been manually classified by a trained “musicologist”, through a process that takes almost 20 minutes.
Once we had a training sample, we needed to tell our algorithm which attributes of the firm to use for training and classification. Every answer to a question in the survey is an attribute of a firm in our data. As many of them are correlated, and also not informative about the type and stage of the firm, we performed feature selection using the gain ratio metric.
We tested several classification algorithms and chose one that was highly accurate and well predicting for our data. Accuracy was determined using cross validation on our trained data.
Identifying inconsistency
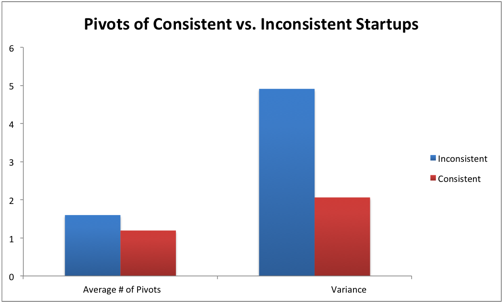
Using our training data, we checked what happens when the actual stage of a firm does not match its behavioral stage. The results (described in the report) show strong evidence that premature scaling is a major cause for startup lackluster performance.
Premature scaling happens when a firm advances in one (or more) of its operational dimensions without syncing it with the rest of its operations. This behavior results in a myriad of issues, such as inability to raise money in later stages, or spending too much on marketing too early, causing customer dissatisfaction.
Our classification algorithm uses the predicted actual and behavioral stages to identify inconsistent firms. The data for these firms is then compared to other firms of the same stage and type.
Transforming math into code
Most of the analysis was done using Weka, with final touches in Excel. Once we had our classification methodology working, our developers transferred the algorithm into a web application that is able to perform both training and classification for the firms filling out the survey.
Visualization
A major investment on our part was to be able to let firms analyze and benchmark themselves against other firms. The amount of information we display to firms includes 23 measures, on top of their Type, Stage and whether they are inconsistent and a personalized research from the Startup Genome Report.
It was therefore very important that our presentation method be both appealing visually, but also informative, allowing a firm to easily separate the wheat from the chaff.
On each measure of the report, we compare each firm to the mean of other firms in its group, and display it location compared to the majority of the group, defined as 1 standard deviation from the mean.
The usual suspects
Some caveats about our process require mentioning:
In addition to the introduction of the Startup Genome Compass, we are releasing a second report that goes deeper into analysis of startups; mainly the implications of prematurely scaling their operations.
The Startup Genome Compass is a result of further research into the properties of startups, and what makes them tick. Several months ago, we published the first Startup Genome Report. The report received tremendous attention, and wide publication. Over 3,200 firms filled out our assessment, and we received excellent feedback and support from the startup ecosystem.
This blog post describes how the Startup Genome Compass was built, and some of the magic behind the curtain. Before I begin, it may be worthwhile to remind the readers about the goal of the project:
The Startup Genome project aims to increase the success rate of startups by deciphering how startups are built, and give entrepreneurs data, tools and recommendations to improve their performance. We try to put quantitative measures on almost all aspects of startup performance in order to improve decision making during the lifetime of firms.
The "heart" of our technology lies in the machine learning process used to identify the startup’s type and stage. The credit for building and fine tuning the machine learning engine goes to Ertan Dogrultan, who became an indispensable member of the Startup Genome team in June. I describe the machine learning process later in the blog post. Before that, here's a short introduction to Machine Learning.
The idea behind machine learning is simple - given a set of examples, called the training sample, an algorithm "can learn" the common patterns in these examples, and try to find these patterns in a new set of data. For example, we can give an algorithm a set of peoples' heights and genders. The algorithm can then learn that men are, on average, taller than women. When the algorithm is given a new set of data on people later, it can predict their average height from their gender.
What machine learning does best is to identify the relevant parameters that can describe a pattern in the data succinctly, learn those patterns and then predict them. In other words, it is good at identifying correlations and interpolating from data.
What machine learning does not do, typically, is explain the process that causes these correlations, or what causes what. I touch a little bit on that later, in the part titled "the usual suspects", but in general, readers of our report should always remember that correlation does not imply causation.
In the next few paragraphs, I will describe the analysis process in the order it was performed, leading to the development of the Startup Genome Compass.
Data Collection
Given the overwhelming response to our report, we were able to collect a significant amount of data. Some researchers have estimated that the Startup Genome now has the largest collection of startup data in the world. The role of our data collection in this phase was less exploratory and more targeted. The major change from version 1 of the survey was addition of specific questions that could help identify startup type and stage. In addition, we collected more "generic" information (such as age and education information) to be able to compare our findings with previous research about the startup phenomena. Another improvement over the previous survey was making it dynamic - during the survey, the questions changed on the fly according to firms' answers, thus allowing us to ask more questions.
Machine Learning for Classification
In order to analyze a firm, we need to classify it to two types of groups - what type of firm it is, and in which stage it is. It is important to understand the difference between a behavioral stage and an actual stage of a firm.
A behavioral stage is determined according to the firm's actions, e.g., how much money it spends on user acquisition, or how many employees it has hired. An actual stage is determined by a firm's market success factors. Examples are the user growth of the firm, its total number of users and other measures. In total there are several tens of parameters used for each classification.
A classic classification process has two parts - in the first part, called training, an algorithm is given examples of exogenously classified data. This data is used to train the algorithm to be able to analyze non-training data. In the second part, classification is run on the non-classified data, and the results are tested for accuracy.
Our training data was created by our team. We manually classified several hundreds of firms for types, behavioral stage and actual stage. It was a lot of work, but the more firms we classified, the more accurate our algorithm becomes. Pandora works similarly, actually. Every song you hear has been manually classified by a trained “musicologist”, through a process that takes almost 20 minutes.
Once we had a training sample, we needed to tell our algorithm which attributes of the firm to use for training and classification. Every answer to a question in the survey is an attribute of a firm in our data. As many of them are correlated, and also not informative about the type and stage of the firm, we performed feature selection using the gain ratio metric.
We tested several classification algorithms and chose one that was highly accurate and well predicting for our data. Accuracy was determined using cross validation on our trained data.
Identifying inconsistency
Using our training data, we checked what happens when the actual stage of a firm does not match its behavioral stage. The results (described in the report) show strong evidence that premature scaling is a major cause for startup lackluster performance.
Premature scaling happens when a firm advances in one (or more) of its operational dimensions without syncing it with the rest of its operations. This behavior results in a myriad of issues, such as inability to raise money in later stages, or spending too much on marketing too early, causing customer dissatisfaction.
Our classification algorithm uses the predicted actual and behavioral stages to identify inconsistent firms. The data for these firms is then compared to other firms of the same stage and type.
Transforming math into code
Most of the analysis was done using Weka, with final touches in Excel. Once we had our classification methodology working, our developers transferred the algorithm into a web application that is able to perform both training and classification for the firms filling out the survey.
Visualization
A major investment on our part was to be able to let firms analyze and benchmark themselves against other firms. The amount of information we display to firms includes 23 measures, on top of their Type, Stage and whether they are inconsistent and a personalized research from the Startup Genome Report.
It was therefore very important that our presentation method be both appealing visually, but also informative, allowing a firm to easily separate the wheat from the chaff.
On each measure of the report, we compare each firm to the mean of other firms in its group, and display it location compared to the majority of the group, defined as 1 standard deviation from the mean.
The usual suspects
Some caveats about our process require mentioning:
- Applicability to a firm - Reporting average results does not necessarily mean that firms should aspire to change their behavior to match the mean. To put it in other words, you don't tell children who get an A+ in a test to try and get a B in the next time. Our application helps point out where firms deviate significantly from the behavior of the majority. We recommend that entrepreneurs use this is a tool to identify potential issues with their firm.
- Classification error - Since we are using statistics to classify firms, our algorithm may have classification errors. This might mean that some firms may be classified into an incorrect type or stage. In our tests, the amount of error is very small, given the large number of variables we are using. The solution to this issue is to identify the causes of these errors, and improve our survey and analysis to handle them. More data is also needed to help with this issue. Therefore, each firm that fills out the survey also contributes to the future enhancement of its own analysis.
- Survivability Bias - As mentioned in Jason's excellent blog post, our data is static. We do not have any firms that ceased to exist fill out our survey and tell us why they have failed. Our stages model solves this problem partially, as we are able to put a measure which is better than "dead" or "alive" on firms. We are striving to move from our static analysis of the firm to a more dynamic model of firm performance, which is where our focus will lie in future versions.
What's next for us?
We are very excited about launching the Startup Genome Compass, and we hope it will be useful to the startup community. Our current focus is on collecting more data and improving our surveying mechanism to improve the accuracy of our analysis. The next step is introducing dynamic analysis of startups, which we believe will disrupt the field of startup analysis.
Stay tuned...